前後端驅動是虛拟化的重要組成部分,在我們平時的排查過程中,經常會涉及到這部分的資料,特别是與性能相關的問題類型。舉個例子,我們經常會碰到網絡抖動的問題,此時我們會在執行個體内部和後端vif口抓包,如果發現兩者之間存在延遲,經常我們就會懷疑到前後端的問題。是以我們需要對其工作原理和排查方法需要有一個全面的了解,其中也涉及到一些調試技巧,如為了确定問題是否與前後端隊列有關,需要在執行個體系統的core dump内解析出記憶體中的隊列資料。
https://www.atatech.org/articles/111810#0 何為前後端:
說到前後端就要提到virtIO,virtIO是IBM提出的實作虛拟機内部和主控端之前資料交換的一種方式,與之前所謂全虛拟化方式比較即通過qemu在模拟裝置的方式,性能有了較大的提升。我們在本文中僅局限于網卡裝置,這也是因為在執行個體案例中網絡部分占了主導地位。簡單來講,在virtIO體系中分為前端驅動和後端驅動兩個部分,前端驅動我們一般可以了解為虛拟機内部的虛拟網卡的驅動,當然Windows和Linux的驅動是不同的,後端驅動virtIO是主控端上的部分 的實作可能會有不同的方式,我們常見的是vhost-net,核心模式的vhost,至于其他模式如使用者态vhost、qemu等等又有不同,但是本質的功能是類似的,就是将前端驅動發出的封包轉發到NC虛拟交換機上,同理将收到的封包傳入執行個體内的前端驅動。
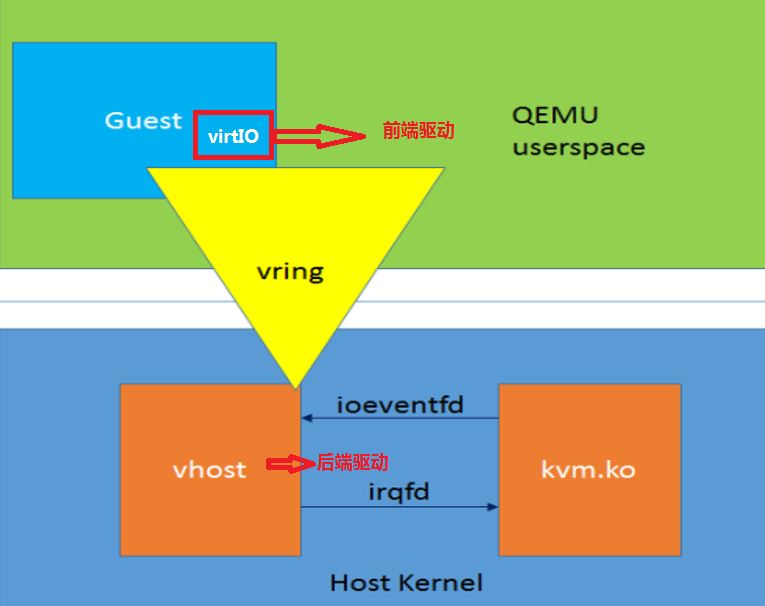
上面這張圖表示了前面驅動和後端驅動的關系。簡單來講前端驅動就是虛拟機内的虛拟網卡驅動,而後端驅動是主機上的vhost程序負責将封包轉發出來,或者将實體機上接受到的封包轉發進虛拟機。這兩者其實就是負責了虛拟機内外的資料交換。
https://www.atatech.org/articles/111810#1 前後端之間如何交換資料
總的來說兩者是通過vring、或者說virt queue即前後端環形隊列進行資料交換。一共存在三個隊列:
crash> struct vring
struct vring {
unsigned int num;
struct vring_desc *desc;
struct vring_avail *avail;
struct vring_used *used;
}
- desc隊列 - 放置了所有真正的封包資料。
- avail隊列與used隊列 - 在發送封包的時候,前端驅動将封包在desc中的索引放在avail隊列中,後端驅動從這個隊列裡擷取封包進行轉發,處理完之後将這些封包放入used隊列。在接受封包的時候前端驅動将空白的記憶體塊放入avail隊列中(當然也隻是封包在desc隊列中的索引而已),後端接受封包将内容填充後,将這些含資料的封包放入used隊列。
這三個隊列都是固定長度的環形隊列,當然實作僅僅是對相應索引号對最大長度去餘而已。下面這張圖形象地表明三個隊列和前後端驅動的關系:
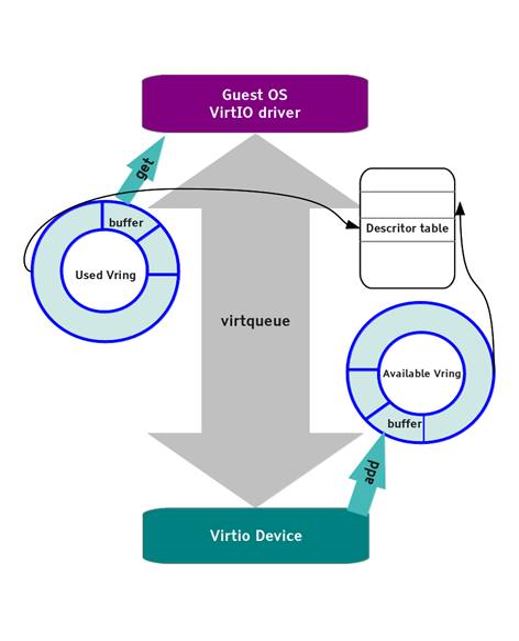
https://www.atatech.org/articles/111810#2 主要的資料結構
我們以前端的發送隊列為例,注意所有的結構資訊都是在虛拟機内部可見的,可以通過core dump檢視:
struct vring_virtqueue {
vq = {
list = {
next = 0xffff881027e3d800,
prev = 0xffff881026d9b000
},
callback = 0xffffffffa0149450,
name = 0xffff881027e3ee88 "output.0", ->>表明是發送隊列
vdev = 0xffff881023776800,
priv = 0xffff8810237d03c0
vring = {
num = 256, ->>所有的隊列長度
desc = 0xffff881026d9c000, ->> desc隊列
avail = 0xffff881026d9d000, ->> avail隊列
used = 0xffff881026d9e000 ->> used隊列
broken = false,
indirect = true,
event = true,
num_free = 0, ->> 隊列目前有多少空閑元素了,如果已經為0表明隊列已經阻塞,前端将無法發送封包給後端
free_head = 0, ->> 指向下一個空閑的desc元素
num_added = 0, ->>是最近一次操作向隊列中添加封包的數量
last_used_idx = 52143, 這是前端記錄他看到最新的被後端用過的索引(idx),是前端已經處理到的used隊列的idx。前端會把這個值寫到avail隊列的最後一個元素,這樣後端就可以得知前端已經處理到used隊列的哪一個元素了。
<> ->> last_avail_idx 前端不會碰,而且前端的virtqueue結構裡就沒有這個值,這個代表後端已經處理到avail隊列的哪個元素了,前端靠這個資訊來做限速,後端是把這個值寫在used隊列的最後一個元素,這樣前端就可以讀到了。
notify = 0xffffffffa005a350,
queue_index = 1,
data = 0xffff881026d9f078
crash> struct vring_avail 0xffff881026d9d000
struct vring_avail {
flags = 0,
idx = 52399, ->> avail隊列的下個可用元素的索引
ring = 0xffff881026d9d004 ->> 隊列數組
crash> struct vring_used
struct vring_used {
__u16 flags;
__u16 idx; ->> used隊列的下個可用元素的索引
struct vring_used_elem ring[]; ->> 隊列數組
https://www.atatech.org/articles/111810#3 封包發送的具體流程
相比接受,封包發送是我們處理案例中主要遇到問題的部分,是以我們将其流程單獨拿出來詳細分析一下。
主要以前端驅動(Linux版本)的行為為主,後端行為設計到阿裡雲源碼實作暫不做分析,但是從前端行為基本可以判斷後端的大緻行為:
- 儲存head = vq->free_head。
- 首先為封包配置設定desc,即封包的描述塊,包含映射到記憶體的封包内容。
- 判斷隊列的num_free是否小于要發送desc元素個數,如果是的話,說明隊列已經阻塞了,後端驅動無法及時處理,是以此時需要通知(notify)後端驅動,前端通知後端的方法就是寫入notification register寄存器。
- 調整num_free減去已經配置設定的desc元素數量。
- 調整free_head指向下一個空閑的desc元素。
- 計算本次應該用avail ring中的哪個元素(即得出元素索引),avail隊列是個環形數組,這裡通過(vq->vring.avail->idx) & (vq->vring.num - 1)達到取餘的目的。
- 記錄本次邏輯buf的起始desc索引号,即将根據剛才得出的元素索引找到相應在avail中的元素,将該元素的值指向本次配置設定desc的元素。這樣處理之後avail隊列中就已經包含了要處理的封包了(當然隻是指向desc的索引而已)
- 調整avail->idx指向了下一次操作使用avail隊列的哪個元素。
- 調整num_added記錄增加了幾個可用的avail ring元素。
- 根據skb->xmit_more的值來決定是否"kick"即通知(notify)後端驅動。xmit_more值代表是否後續還有更多的封包需要發送,如果沒有,前端驅動就會決定kick,如果有前端驅動會繼續等待其他封包進入隊列後再一起"kick"。
- 在決定是否要notify後端驅動時,這裡有一個限速邏輯:
- 首先提取used隊列中最後一個元素,這是後端填入的資訊,表示後端驅動處理到哪個avail隊列的元素了,将值儲存到event_idx。
- 記錄上一次avail隊列idx索引的值到old。
- 記錄這一次封包進入隊列之後avail隊列idx索引的值到new_idx。
-
于是這裡有一個公式來最後決定是否要notify後端驅動,即所謂的限速邏輯:
(new_idx - event_idx - 1) < (new_idx - old)
用一張圖來表示這個限速邏輯:
第一種情況,目前後端處理速度很快,前端應當notify後端驅動:
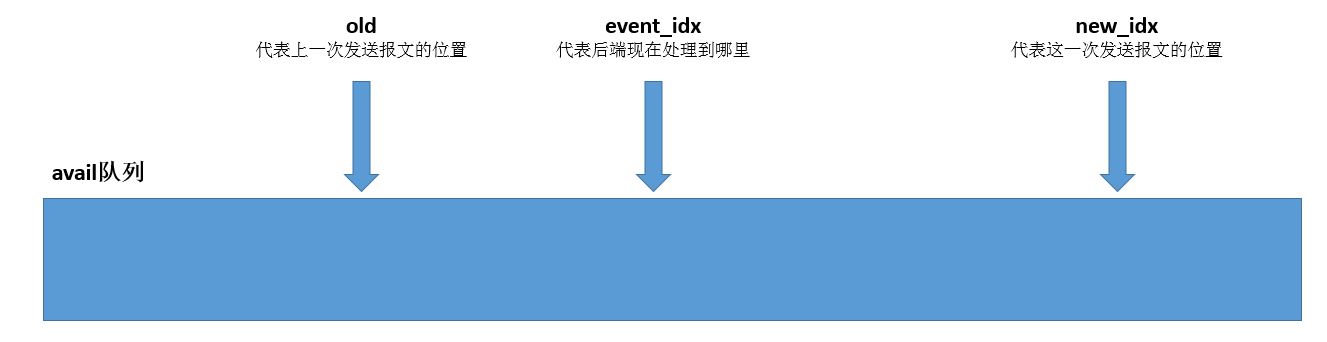
第二種情況,後端處理速度跟不上前端發送封包速度,暫時不要notify後端:

https://www.atatech.org/articles/111810#4 前端隊列的狀态分析
這裡介紹的主要是通過core dump分析前端隊列的方法,後端由于涉及到線上實體機,我們往往無法進行有效的分析。
https://www.atatech.org/articles/111810#5 Linux Core Dump
由于後端缺乏詳盡的日志,我們往往需要依賴前端進行分析,而前後端隊列的狀态是在核心态,是以core dump是成了比較重要的分析手段了。以下介紹怎樣通過Linux Core Dump對前後端隊列進行分析:
首先通過net指令可以直接擷取所有net_device的位址:
crash> net
NET_DEVICE NAME IP ADDRESS(ES)
ffff881028c66020 lo 127.0.0.1
ffff8810225f5020 eth0 172.20.1.13
擷取其中的device位址:
crash> struct net_device ffff8810225f5020 -o | grep device
struct net_device {
[ffff8810225f50a0] struct net_device_stats stats;
[ffff8810225f5168] const struct net_device_ops *netdev_ops;
[ffff8810225f5198] struct net_device *master;
[ffff8810225f5408] struct net_device *link_watch_next;
[ffff8810225f5418] void (*destructor)(struct net_device *);
[ffff8810225f5450] struct device dev; --->> device位址
擷取其中的parent指針:
crash> struct device ffff8810225f5450 | grep parent
parent = 0xffff881023776810,
将結果減去10就是virtio_device結構:
crash> struct virtio_device ffff881023776800 -o
struct virtio_device {
[ffff881023776800] int index;
[ffff881023776804] bool config_enabled;
[ffff881023776805] bool config_change_pending;
[ffff881023776808] spinlock_t config_lock;
[ffff881023776810] struct device dev;
[ffff881023776a30] struct virtio_device_id id;
[ffff881023776a38] struct virtio_config_ops *config;
[ffff881023776a40] struct list_head vqs; ----->> 所有隊列的位址
[ffff881023776a50] unsigned long features[1];
[ffff881023776a58] void *priv;
列出所有隊列的位址:
crash> list ffff881023776a40
ffff881023776a40
ffff881026d9b000 ->> input.0 接受隊列
ffff881026d9f000 ->> output.0 發送隊列
ffff881027e3d800 ->> control控制指令隊列
我們一般比較多關注發送隊列,是以挑選發送隊列來看:
crash> struct vring_virtqueue ffff881026d9f000
name = 0xffff881027e3ee88 "output.0",
num = 256,
desc = 0xffff881026d9c000,
avail = 0xffff881026d9d000,
used = 0xffff881026d9e000
num_free = 0, ----->> 表明隊列已滿
free_head = 0,
num_added = 0,
last_used_idx = 52143,
當然還可以打出desc、avail和used每個數組的情況。
![linux-svn解除安裝與安裝[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)