對于資料庫的使用者而言,索引是一個非常熟悉的概念。Wikipedia中對資料庫索引的定義:
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure.
使用者建立索引的期望是能夠避免全量掃描,通過索引來減少IO和CPU開銷進而加速查詢,是典型的空間換時間的優化方式。大部分資料庫會預設建立主鍵/RowKey索引,二級索引等其它類型索引需要使用者根據實際查詢情況自定義地建立。
阿裡雲圖資料庫GDB對于使用者點邊的每一個屬性都會自動建立索引資訊,減少使用者額外的索引操作。同時,使用者也可以根據通路場景通過GDB支援的标準圖查詢語言
Gremlin動态地建立複合索引、唯一索引和點中心索引等其它類型的索引來加速特定的查詢。
自動索引
LDBC SNB是面向圖資料管理系統的Benchmark,越來越受到圖資料庫廠商的重視,下面以LDBC SNB的資料模型為例來說明圖資料庫GDB的自動索引是如何工作的。
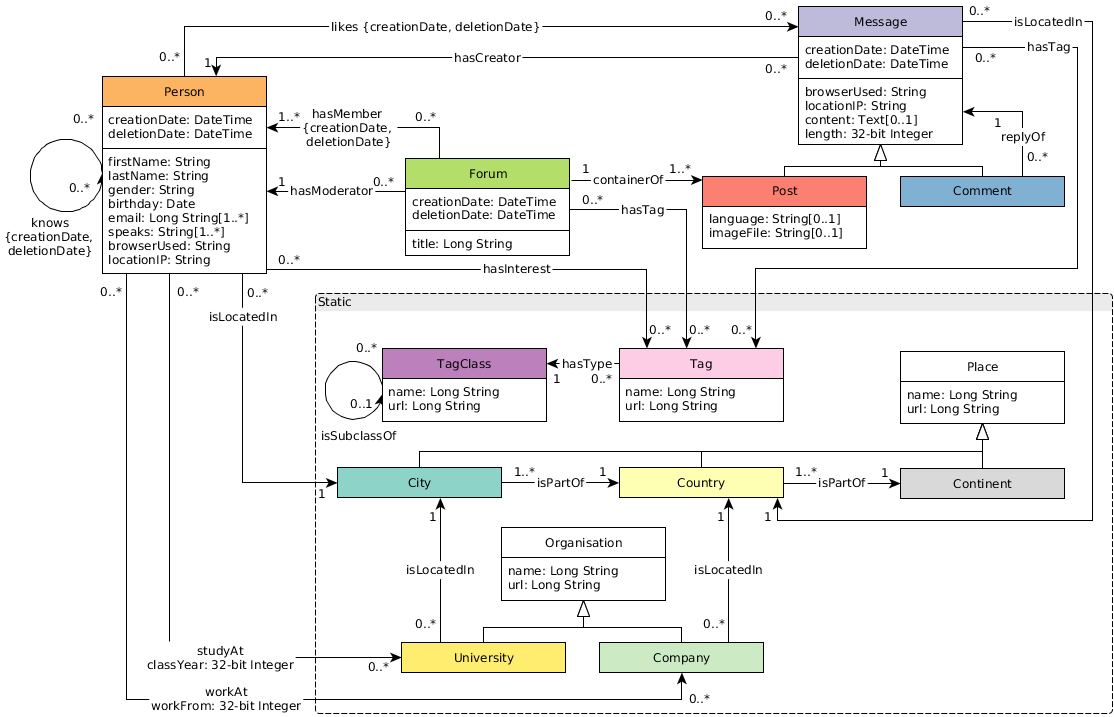
從模型中可以看出,對于Person這種Label的節點,可能會有firstName、lastName、creationDate等多種屬性。當使用者使用Gremlin DSL插入某個節點的資料時:
g.addV('Person').property('firstName', 'Foo').property('lastName', 'Bar').property('creationDate', 20200225) 圖資料庫GDB會自動為每一個屬性fistName、lastName、creationDate建立索引資料。這樣查詢firstName為Foo的人時,查詢語句會自動利用對應的索引來擷取結果,避免周遊操作:
g.V().hasLabel('Person').has('firstName', 'Foo')
# 下面的這些查詢也會利用自動索引
g.V().hasLabel('Person').has('firstName', TextP.startingWith('Fo'))
g.V().hasLabel('Person').has('creationDate', gte(20200101)) 如果需要根據fistName、lastName來進行查找:
g.V().hasLabel('Person').has('firstName', 'Foo').has('lastName', 'Bar') 圖資料庫GDB會根據内部統計資訊來決定使用firstName索引還是lastName索引。但是,如果圖資料庫中firstName為Foo以及lastName為Bar的節點資料都非常多時,通過自動索引掃描出來的資料也會非常多,這個時候就需要手動建立複合索引了。
複合索引
上面一節提到了同時對firstName和lastName進行過濾的查詢需要建立複合索引,在阿裡雲圖資料庫GDB中,我們可以友善地使用Gremlin DSL來進行添加索引的操作:
gremlin> g.withSideEffect("GDB#createVertexLabelIndex", "{label: 'Person', properties: ['firstName', 'lastName'], unique: false}").inject(1)
==>GraphDbIndex
Index created, id: 1 建立之後可以通過Gremlin DSL查詢對應的索引的狀态:
gremlin> g.withSideEffect("GDB#queryIndex", "all").inject(1)
==>GraphDbIndex
Id: 1, Desc: { type: 0, label: Person, property_list: [ firstName, lastName ], unique: false }, Status: Installed 當索引狀态從Populating變為Installed之後,對應的索引就能夠被查詢語句利用到了。
點中心索引
點中心索引是針對“一跳場景”過濾非常實用的一種索引類型。下圖是社交網絡場景的例子,Vertex是注冊使用者,Edge是關注關系,Edge上有一個屬性since代表關注時間。

假設一個大V有100w+的粉絲,現在需要找出大V的粉絲中“關注時間在10年以上的”,在沒有索引可以利用的時候,我們需要周遊100w+的粉絲進行過濾。這時候就會有一個問題:能否針對這個大V的100w+粉絲進行排序,按照since來進行排序 ,這樣這不需要進行全量的掃描了。這個問題的答案就是阿裡雲圖資料庫GDB的點中心索引。
下面還是使用LDBC SNB的資料為例來說明點中心索引如何建立和使用,LDBC SNB的資料模型中Person節點會建立到其它Person節點數的邊,類型為knows,邊上有屬性creationDate代表開始時間。現在需要查詢某一個Person節點最近認識的10個人,傳回他們之間的邊和對應的creationDate,對應的查詢語句如下:
g.V('p4398046512014').bothE('knows').
order().by('creationDate', desc).
project('relation', 'date').
by(identity()).
by(values('creationDate')).
limit(10) 基于
這裡的資料看下上面這條Gremlin DSL運作的時間:
gremlin> g.V('p4398046512014').bothE('knows').
......1> order().by('creationDate', desc).
......2> project('relation', 'date').
......3> by(identity()).
......4> by(values('creationDate')).
......5> limit(10).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphDbGraphStep(vertex,[p4398046512014]) 1 1 0.263 1.61
VertexStep(BOTH,[knows],edge) 426 426 4.964 30.34
OrderGlobalStep([[value(creationDate), desc]]) 11 11 10.593 64.74
RangeGlobalStep(0,10) 10 10 0.032 0.20
ProjectStep([relation, date],[[IdentityStep, Pr... 10 10 0.509 3.11
IdentityStep 10 10 0.007
PropertiesStep([creationDate],value) 10 10 0.277
>TOTAL - - 16.362 - 現在對knows類型的邊加上點中心索引,操作方式和上面添加複合索引的方式類似:
gremlin> g.withSideEffect("GDB#createVertexCentricIndex", "{label: 'knows', properties: ['creationDate'], direction: 'BOTH'}").inject(1)
==>GraphDbIndex
Index created, id: 2 同樣的語句再來看一下運作時間:
gremlin> g.V('p4398046512014').bothE('knows').
......1> order().by('creationDate', desc).
......2> project('relation', 'date').
......3> by(identity()).
......4> by(values('creationDate')).
......5> limit(10).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
GraphDbVertexCentricStep(edge,[java.lang.Object... 11 11 2.854 78.41
RangeGlobalStep(0,10) 10 10 0.047 1.29
ProjectStep([relation, date],[[IdentityStep, Pr... 10 10 0.739 20.30
IdentityStep 10 10 0.030
PropertiesStep([creationDate],value) 10 10 0.442
>TOTAL - - 3.640 - 對于這個測試資料集,同樣查詢語句的延遲從16.3ms縮短到了3.64ms,從Profile的結果可以看到添加了點中心索引,GDB增加了定制過的GraphDbVertexCentricStep。當然,這個測試資料集中對應的點隻有426條邊,對于真實業務而言,添加合适的點中心索引可能會帶來數十倍的性能提升。
結束語
阿裡雲圖資料庫GDB支援的自動索引,可以滿足大部分業務場景的查詢需求,很大程度上節省了使用者接入的時間,同時使用者可以根據查詢情況定制更多的索引來提升特定場景的性能。圖資料庫的場景中還可以衍生出更多有意思的索引類型,比如子圖比對場景的索引、針對節點可達性查詢的索引等,讓使用者以更快的速度探索互聯資料的奧秘。