Abstract
清華大學和一些企業合作的文章,發表于ICCV 2017.文章主要
目前,大多數的圖檔解析模型都将所有尺寸和位置的資訊同等對待,而沒有考慮汽車捕獲的城市場景圖檔的幾何屬性. 是以,由于攝像頭的透視投影,會導緻存在不同的物體尺寸,并且不可避免地造成場景解析和識别錯誤.
本方法在Cityscapes和Camvid上達到了SOTA.
本文的主要貢獻:(1)提出透視評估網絡來學習城市街景圖檔中的全局透視幾何資訊(2)提出考慮透視的解析網絡進行城市街景中差異化尺寸問題的解決方法(3)提出考慮透視的CRFs模型來減少大尺寸物體存在的“分解”問題.
Movitation
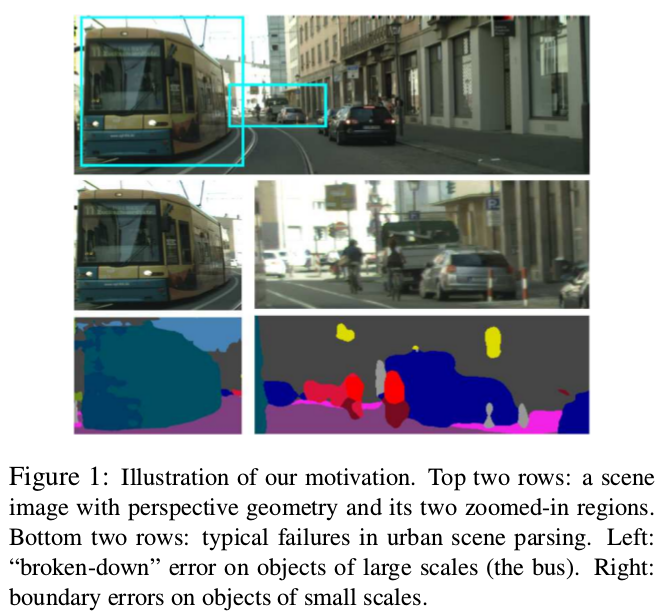
在攝像頭下近的物體拍出來比較大,遠的物體拍出來比較小,然而在現實中可能是同樣大小的物體.通常的分割方法,由于忽略了這種資訊,常常導緻将一個大的物體分解,同時小的物體邊界也容易産生錯誤. 是以考慮提出FoveaNet結合這種資訊.
Frame

主要想法是預測一張圖檔中的透視幾何,然後對不同尺寸的資訊進行不同的解析,而不是統一解析.
-
考慮透視的評估網絡
主要是更好的解析消失點附近的小尺寸物體聚集區域.這裡提出Perspective Estimation Network(PEN)如下:
[FoveaNet]FoveaNet: Perspective-aware Urban Scene ParsingAbstractMovitationFrameResultCode 使用Deeplabv2-ResNet101的基本架構,然後res5不進行downsampling,最終得出的結果是原圖的1/16.
這裡圖檔的ground truth如下:
[FoveaNet]FoveaNet: Perspective-aware Urban Scene ParsingAbstractMovitationFrameResultCode 其中n表示第n張圖,m是圖中的執行個體,表示像素,l(m)表示執行個體m的類别,AveSize(l(m)),表示執行個體m在類别等級的平均大小.
最終形成的heatmap圖如下:
[FoveaNet]FoveaNet: Perspective-aware Urban Scene ParsingAbstractMovitationFrameResultCode -
考慮透視的CRF
主要是解決大尺寸物體的“分解”問題.
CRF這一部分有空進行一下總結.
Result
在Cityscapes的圖檔訓練中,将圖檔randomly crop為896x896.
在兩個資料集上的性能并不是特别高,并沒有PSPNet, Tusimple等高.
Code
None