先說一下結論:包裝類直接添進去,能保證不會重複添加。如果是自定義類,重寫以屬性内容生成hashcode的方法,别重複添加修改屬性後的同位址對象。
下面是對源碼分析和證明部分,有誤望指出!
一、什麼是hashcode?
百度解釋

1.可以簡單了解為将任意長資料經雜湊演算法變為固定長度的一串數字。
2.不同資料生成的hashcode有可能相同,我們稱之為哈希碰撞。
二、對象位址,屬性,hashcode之間的關系梳理
1.先上一張總關系圖,可以邊打開圖放一邊,一邊看我文字描述。

2.在java中生成對象的hashcode有兩種方式
1、隻根據位址生成hashcode
Cat類中重寫該方法
@Override
public int hashCode() {
return super.hashCode();
}
測試同屬性不同位址下hashcode的生成情況:
@Test
/**
* 測試隻根據位址生成hashcode是否成立
*
*/
public void test1(){
Cat mm = new Cat("喵喵");
System.out.println(mm.hashCode());
Cat mm1=new Cat("喵喵");
System.out.println(mm1.hashCode());
}
結果為:
1859039536
278934944
結論:說明這種方法生成的hashcode隻與位址有關與屬性無關。同一位址的對象的屬性值可以随便更換(看總關系圖)。
【注意】這裡hashcode定長是指二進制定長32,即4位元組,可用整型來存儲
2.隻根據屬性生成hashcode
Cat類重寫該方法
@Override
public int hashCode() {
return Objects.hash(getName());//隻根據屬性
}
測試同位址不同屬性情況下的hashcode:
@Test
/**
* 測試隻根據屬性生成hashcode是否成立
*
*/
public void test2(){
Cat m1 = new Cat("喵喵");
System.out.println(m1.hashCode());
m1.setName("喵嗚");
System.out.println(m1.hashCode());
}
結果:
702143
701798
結論:說明隻根據屬性生成hashcode的方法也成立。同一個屬性可以被多個不同位址的對象引用(看總關系圖)。
三、向HashSet添加元素時的關鍵源碼分析
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//表示如果是第一次添加,那就先擴容,這裡預設初始化為16個Node長度的 數組
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根據hash值運算得到待添加key值該放到數組哪裡去,如果運算得到待添入位置出沒有已存在的Node,那就建立個Node,Node裡存好key,把Node存進該Node數組的該位置處
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//如果計算出的數組待添入位置處有Node了,則進一步比較判斷是否加入
Node<K,V> e; K k;
//這裡是數組處與數組處重複了該執行的操作(核心)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果數組位置處挂着一顆紅黑樹,則用這個判斷是否添入
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//周遊數組該位置處連着的子鍊
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//重複了就執行這個
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
四、添加不同元素可能出現的情況
回到總關系圖
情況1:如果已存在null值那麼經計算得到的hashcode肯定一樣,再計算出來的在數組中的位置肯定也一樣,那麼必然要經過這道考驗if (p.hash != hash || ((k = p.key) != key && !(key != null && key.equals(k))));數組該位置處子鍊上可能除了null還有其他元素,跟其它元素比較時如果p.hash!=hash為true則比較子鍊下一個,如果運算出來是false,則發生了hash碰撞,那麼看後邊p.key!=key也為true,!(key != null && key.equals(k)))也為true,那麼得出結論,hash值不同就繼續檢索,發生hash碰撞就加上後邊判斷條件,按這種判斷條件,如果内容不是null,即使hash碰撞也要繼續往下檢測,直到發生hash碰撞并後邊判斷null==null才不讓加。
代碼驗證:
@Test
/**
* 在位址生成hashcode情況下
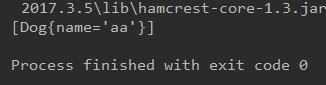
* 位址同,内容改,看是否會重複添加?
* [Dog{name='bb'}]不會重複,隻會改,即保證不會重複添加同位址對象
*/
public void test2(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
hashSet.add(aa);
aa.setName("bb");
hashSet.add(aa);
System.out.println(hashSet);
}
@Test
/**
* 在位址生成的hashcode情況下
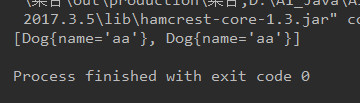
* 測試位址不同,内容相同是否可添加
*[Dog{name='aa'}, Dog{name='aa'}]可添加
*/
public void test3(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
Dog a2= new Dog("aa");
hashSet.add(aa);
hashSet.add(a2);
System.out.println(hashSet);
}```
情況2:如果計算出的位置處啥也沒有,那肯定直接添,如果有但又不是已存在其它元素則類似情況1,因為沒有null,是以一直往下成功檢索,檢索到子鍊尾并添加。
【注意】java1.8之後null的hashcode固定為0,之前null都沒有hashcode不允許加入到hashSet或hashMap。總節之,null就是單純的不可重複添加。
情況3、4、5、6:這又得看是重寫了以位址生成hashcode方法還是以屬性生成hashcode方法。
1:如果以位址生成hashcode,如果裡邊已經存着一個同位址的,當沒檢索到存着同位址的那個Node頭上時,一般來說沒有hash碰撞,p.hash!=hash為true這樣就直接獲得繼續檢索的資格,如果發生hash碰撞,p.hash!=hash為false那麼繼續進行判斷,p.key!=key為true,繼續判斷!(key != null && key.equals(k)),這裡如果屬性相同則為false,那麼整個判斷為false,那麼就失去檢索資格,被判定為重複。剛好檢索到存着同位址的那個Node時,那麼hash值 肯定一樣,p.hash!=hash為false,p.key!=key為false這時就不用看了,肯定在這就停了,它失去了添加的資格。
【總結】這種以位址生成hashcode,在添加時,能保證同位址的絕對不添加,但修改位址上的内容可以時hashSet裡的内容同步修改。不同位址的放進去如果一直沒有hash碰撞,則直接放進去,會導緻屬性重複的放進去。如果hash碰撞還能夠檢測到屬性内容重複,直接勸退。是以用位址生成hashcode隻能保證存放的對象位址肯定不一樣,其它就不能保證了。
2.如果以屬性内容生成hashcode,如果裡邊已經存着一個同屬性内容的,當沒檢索到存着同屬性的那個Node頭上時,一般來說沒有hash碰撞,p.hash!=hash為true這樣就直接獲得繼續檢索的資格,如果發生hash碰撞,p.hash!=hash為false,繼續判斷p.key!=key為true,在屬性位址存在于同一對象位址時,為false,那麼停止檢索,失去添加資格,如果屬性存在于其它位址對象,為true,那麼繼續進行判斷,!(key != null && key.equals(k))為true,繼續檢索。剛好檢索到存着同屬性的那個Node時,那麼hash值 肯定一樣,p.hash!=hash為false,p.key!=key為false這時就不用看了,肯定在這就停了,它失去了添加的資格,如果為ture,!(key != null && key.equals(k))為false,當場拒絕添加。
【總結】這種以屬性内容生成hashcode,在添加時僅保證同屬性内容的絕對不會添加,但不同屬性同位址在沒有hash碰撞時仍能添加,這就導緻hashSet内會存在兩個重複對象重複屬性,不同屬性同位址在發生hash碰撞就可以阻止同位址的重複添加。
代碼驗證:
```java
@Test
/**
* 在屬性生成hashcode情況下
* 位址同,内容改,看是否會重複添加?
* [Dog{name='bb'}, Dog{name='bb'}]會重複
*/
public void test4(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
hashSet.add(aa);
aa.setName("bb");
hashSet.add(aa);
System.out.println(hashSet);
}
@Test
/**
* 在屬性生成的hashcode情況下
* 測試位址不同,内容相同是否可添加
*可添加
*/
public void test5(){
HashSet hashSet = new HashSet();
Dog aa = new Dog("aa");
Dog a2= new Dog("aa");
hashSet.add(aa);
hashSet.add(a2);
System.out.println(hashSet);
}```
【大總結】一般我們往hashSet裡添對象都不會添重複位址的對象,這就減少了重複添位址的機率,這在以位址生成hashcode情況下,還有添加重複屬性不同對象的可能。但如果以屬性生成hashcode情況下,位址重複機率低,接着保證屬性不會重複添加,就基本保證了位址不同且屬性不同的最終要求。之是以造成這些可能的不符合HashSet不添加重複元素要求的情況,就是因為屬性不是final修飾,可以任意更換。而一般我們存包裝類啥的資料,人家裡邊屬性本身就是final修飾,平時也就用基本資料類型自動轉包裝類型而規避了這些特殊情況。如果要自定義類,然後存裡頭,就可能遇到這些奇奇怪怪的事情。經這次測試研究,得出結論:基本資料類型的包裝類百分百保證重複的添不進。如果想添自定義類,屬性給設成final,奇葩操作造成的混亂可避免掉。如果不能設成final,自個兒注意别重複添同一位址對象,想修改對象内容,疊代周遊找出來,再修改。直接改完再添會出亂子。