postgresql 在向和纵向的扩展能力在开源数据库中一直处于非常领先的地位,例如今年推出的9.6,内置了sharding的功能,同时在scale-up的能力也有非常明显的提升,特别是在多核与高并发处理这块。
社区有同学在128核的机器上测试tpc-b的select only模式可以达到几百万的qps,机器的cpu资源被吃光光。
天下大势,分久必合,合久必分。谈了这么多年的sharding,业务也妥协了这么多年(比如不允许跨shard join,忍受分片不平衡的痛楚,必须要有分区键值,分布式事务,分布式事务一致性等限制或使用门槛)。一个数据库能解决的为什么要分片呢?
原来说用分片去大机,去o,初衷是什么?其实还是太贵对吧。
如今x86的性能已经非常好,ssd也非常廉价,给postgresql一台顶级的x86,能把机器的硬件资源掏空,换来的是非常优秀的性能,还有对应用完全自由的使用,不再受shard的多种约束束缚。
除了读的高并发有明显的性能提升,在写这块,引入了动态扩展数据文件,从而对单个表的插入性能也有非常明显的提升,如果你的应用场景是日志型的,需要大批量的高并发入库,9.6就非常适合你。
lock改进,partition the shared hash table freelist to reduce contention on multi-cpu-socket servers (aleksander alekseev)
本文将针对高并发的读,写,更新场景测试一下9.6和9.5的性能差异。
为了规避io瓶颈的影响,体现9.6代码处理逻辑方面的改进,所有测试场景的数据均小于内存大小。
32核64ht, 512g, ssd, xfs。
全部在本地测试,避免网络的影响,但是本地测试有一个问题就是测试客户端也会占用一定的资源,特别是并发很高的时候,128个连接可能占用掉1/4的cpu资源。
如果网络允许,建议客户端使用另外的机器,比如我后来测试了客户端分离的情况,pg9.6 800个并发连接,tpc-b的查询依旧可以维持在110多万的tps.
测试机器为同一主机。
1. os配置
2. 数据库配置
安装
初始化集群
配置数据库参数
启动数据库
测试时只启动一个数据库,防止干扰。
单表1亿数据量,基于pk的查询。
考察高并发下的代码优化能力。
sql如下
测试结果
并发数 , tps
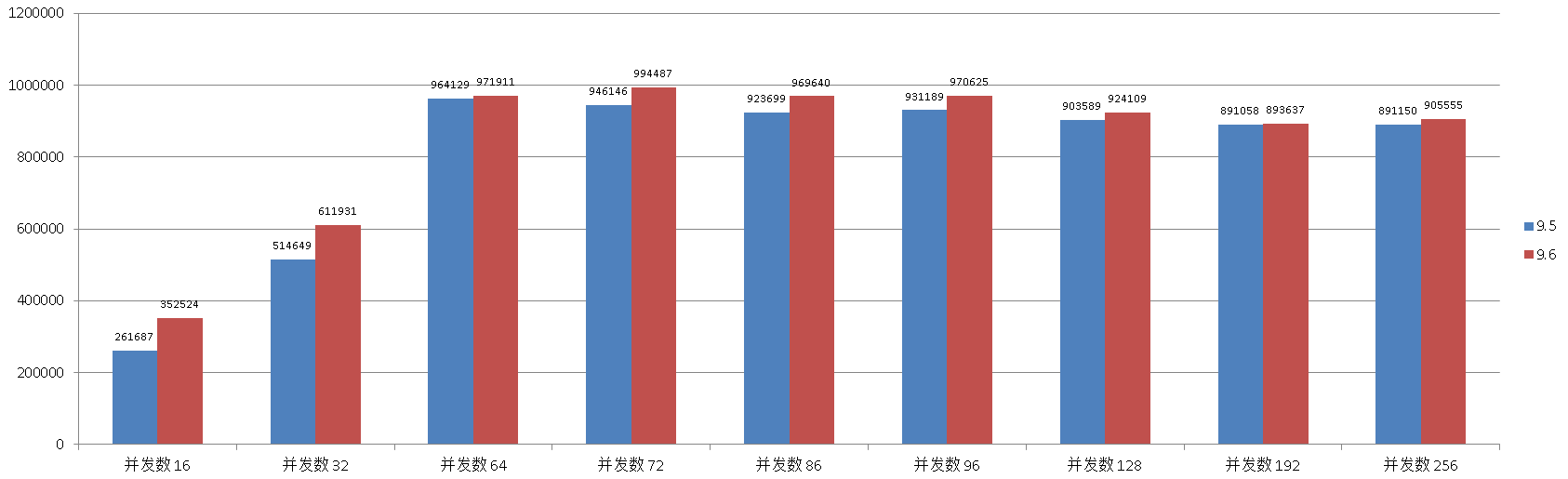
单表1亿数据量,基于pk的更新。
考察高并发下的数据更新,autovacuum优化能力,xlog优化能力。

一张空表,22个字段,每行约201字节,包含两个索引。
采用autocommit的模式,每个连接每个事务插入一条记录。
考察高并发下的数据插入,数据块扩展能力,xlog优化能力。
测试脚本如下
批量插入,考察的同样是高并发处理单表时xlog的优化能力,数据文件的扩展优化能力。
一次插入400条记录。
每个连接对应一张空表,22个字段,每行约201字节,包含两个索引。
考察高并发下的数据插入,xlog优化能力。
与单表不同,因为没有单表的文件扩展并发要求,所以不考察数据块扩展能力。
批量创建测试表,测试脚本
统计
### 环境准备
postgresql 9.6的锁控制能力又有比较大的进步,在wal的高并发管理,获取快照,扩展数据文件等方面都有较大改进,相比9.5在scale-up的扩展能力上又上了一个新的台阶,在高并发的读,插入,更新场景,都有非常明显的性能提升。
结合9.6的多核并行计算,可以适合高并发的tp场景,又能在业务低谷时充分发挥硬件能力,处理ap的报表和分析需求,完成业务对tp+ap的混合需求。
对于3,4,5,6的测试case,由于是批量入库,可以关闭测试表的autovacuum,达到更好的性能。
现在的cpu一直在往多核的方向发展,32核已经是非常普遍的配置,多的甚至可以达到上千核。
使用postgresql可以更好的发挥硬件的性能,虽然postgresql已经在内核层面支持sharding了,但是使用单机能解决的场景,不推荐使用sharding。
目前sharding对应用开发的限制还比较多,比如大多数sharding技术需要解决几个痛点:
分布式事务的控制,跨库join,全局一致性,全局约束,数据倾斜,扩容,备份,容灾,迁移,确保全局一致性的高可用技术。等等一系列需要考虑的问题。