本文緊接上篇《高并發性能測試經驗分享(上)》
雖然解決了core dump,但是另外一個問題又浮出了水面,就是高并發測試時,會出現記憶體洩漏,大概一個小時500M的樣子。
出現記憶體洩漏或者記憶體問題,大家第一時間都會想到valgrind。valgrind是一款非常優秀的軟體,不需要重新編譯程式就能夠直接測試。功能也非常強大,能夠檢測常見的記憶體錯誤包括記憶體初始化、越界通路、記憶體溢出、free錯誤等都能夠檢測出來。推薦大家使用。
valgrind 運作的基本原理是:待測程式運作在valgrind提供的模拟CPU上,valgrind會紀錄記憶體通路及計算值,最後進行比較和錯誤輸出。我通過valgrind測試nginx也發現了一些記憶體方面的錯誤,簡單分享下valgrind測試nginx的經驗:
1.nginx通常都是使用master fork子程序的方式運作,使用–trace-children=yes來追蹤子程序的資訊。
2.測試nginx + openssl時,在使用rand函數的地方會提示很多記憶體錯誤。比如Conditional jump or move depends on uninitialised value,Uninitialised value was created by a heap allocation等。這是由于rand資料需要一些熵,未初始化是正常的。如果需要去掉valgrind提示錯誤,編譯時需要加一個選項:-DPURIFY。
3.如果nginx程序較多,比如超過4個時,會導緻valgrind的錯誤日志列印混亂,盡量減小nginx工作程序,保持為1個。因為一般的記憶體錯誤其實和程序數目都是沒有關系的。
上面說了valgrind的功能和使用經驗,但是valgrind也有一個非常大的缺點,就是它會顯著降低程式的性能,官方文檔說使用memcheck工具時,降低10-50倍。也就是說,如果nginx完全握手性能是20000 qps,那麼使用valgrind測試,性能就隻有400 qps左右。對于一般的記憶體問題,降低性能沒啥影響,但是我這次的記憶體洩漏是在大壓力測試時才可能遇到的,如果性能降低這麼明顯,記憶體洩漏的錯誤根本檢測不出來。隻能再考慮其他辦法了。
address sanitizer(簡稱asan)是一個用來檢測c/c++程式的快速記憶體檢測工具。相比valgrind的優點就是速度快,官方文檔介紹對程式性能的降低隻有2倍。對Asan原理有興趣的同學可以參考asan的算法這篇文章,它的實作原理就是在程式代碼中插入一些自定義代碼,如下:
編譯前:
<code>*address = ...; // or: ... = *address; f</code>
編譯後:
和valgrind明顯不同的是,asan需要添加編譯開關重新編譯程式,好在不需要自己修改代碼。而valgrind不需要程式設計程式就能直接運作。address sanitizer內建在了clang編譯器中,GCC 4.8版本以上才支援。我們線上程式使用的gcc版本較低,于是我測試時直接使用clang重新編譯nginx:
其中with-cc是指定編譯器,with-cc-opt指定編譯選項, -fsanitize=address就是開啟AddressSanitizer功能。
由于AddressSanitizer對nginx的影響較小,是以大壓力測試時也能達到上萬的并發,記憶體洩漏的問題很容易就定位了。這裡就不詳細介紹記憶體洩漏的原因了,因為跟openssl的錯誤處理邏輯有關,是我自己實作的,沒有普遍的參考意義。最重要的是,知道valgrind和asan的使用場景和方法,遇到記憶體方面的問題能夠快速修複。
到此,經過改造的nginx程式沒有core dump和記憶體洩漏方面的風險了。但這顯然不是我們最關心的結果(因為代碼本該如此),我們最關心的問題是:
1.代碼優化前,程式的瓶頸在哪裡?能夠優化到什麼程度?
2.代碼優化後,優化是否徹底?會出現哪些新的性能熱點和瓶頸?
這個時候我們就需要一些工具來檢測程式的性能熱點。
linux世界有許多非常好用的性能分析工具,我挑選幾款最常用的簡單介紹下:
1.perf應該是最全面最友善的一個性能檢測工具。由linux核心攜帶并且同步更新,基本能滿足日常使用。推薦大家使用。
2.oprofile,我覺得是一個較過時的性能檢測工具了,基本被perf取代,指令使用起來也不太友善。比如opcontrol —no-vmlinux , opcontrol —init等指令啟動,然後是opcontrol —start, opcontrol —dump, opcontrol -h停止,opreport檢視結果等,一大串指令和參數。有時候使用還容易忘記初始化,資料就是空的。
3.gprof主要是針對應用層程式的性能分析工具,缺點是需要重新編譯程式,而且對程式性能有一些影響。不支援核心層面的一些統計,優點就是應用層的函數性能統計比較精細,接近我們對日常性能的了解,比如各個函數時間的運作時間,,函數的調用次數等,很人性易讀。
4.systemtap 其實是一個運作時程式或者系統資訊采集架構,主要用于動态追蹤,當然也能用做性能分析,功能最強大,同時使用也相對複雜。不是一個簡單的工具,可以說是一門動态追蹤語言。如果程式出現非常麻煩的性能問題時,推薦使用 systemtap。
這裡再多介紹一下perf指令,tlinux系統上預設都有安裝,比如通過perf top就能列舉出目前系統或者程序的熱點事件,函數的排序。perf record能夠紀錄和儲存系統或者程序的性能事件,用于後面的分析,比如接下去要介紹的火焰圖。
perf有一個缺點就是不直覺。火焰圖就是為了解決這個問題。它能夠以矢量圖形化的方式顯示事件熱點及函數調用關系。比如我通過如下幾條指令就能繪制出原生nginx在ecdhe_rsa cipher suite下的性能熱點:
1.perf record -F 99 -p PID -g — sleep 10
2.perf script | ./stackcollapse-perf.pl > out.perf-folded
3../flamegraph.pl out.perf-folded>ou.svg
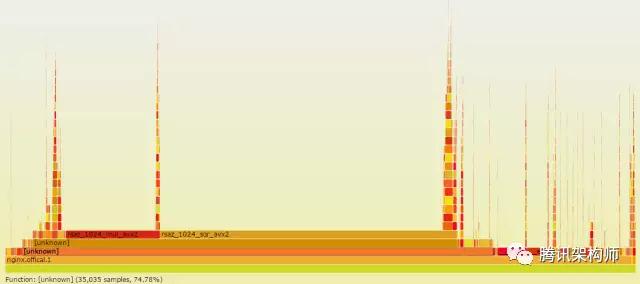
直接通過火焰圖就能看到各個函數占用的百分比,比如上圖就能清楚地知道rsaz_1024_mul_avx2和rsaz_1024_sqr_avx2函數占用了75%的采樣比例。那我們要優化的對象也就非常清楚了,能不能避免這兩個函數的計算?或者使用非本地CPU方案實作它們的計算?
當然是可以的,我們的異步代理計算方案正是為了解決這個問題。

從上圖可以看出,熱點事件裡已經沒有RSA相關的計算了。至于是如何做到的,後面有時間再寫專門的文章來分享。
為了解決上面提到的core dump和記憶體洩漏問題,花了大概三周左右時間。基本上4月份對我來說就是黑色的,壓力很大,精神高度緊張,感覺有些狼狽,看似幾個很簡單的問題,搞了幾周時間。心裡當然不是很爽,會有些着急,特别是項目的關鍵上線期。但即使這樣,整個過程我還是非常自信并且鬥志昂揚。我一直在告訴自己:
1.調試BUG是一次非常難得的學習機會,不要把它看成是負擔。不管是線上還是線下,能夠主動地,高效地追查BUG特别是有難度的BUG,對自己來說一次非常寶貴的學習機會。面對這麼好的學習機會,自然要充滿熱情,要如饑似渴,回首一看,如果不是因為這個BUG,我也不會對一些工具有更深入地了解和使用,也就不會有這篇文檔的産生。
2.不管什麼樣的BUG,随着時間的推移,肯定是能夠解決的。這樣想想,其實會輕松很多,特别是接手新項目,改造複雜工程時,由于對代碼,對業務一開始并不是很熟悉,需要一個過渡期。但關鍵是,你要把這些問題放在心上。白天上班有很多事情幹擾,上下班路上,晚上睡覺前,大腦反而會更加清醒,思路也會更加清晰。特别是白天上班時容易思維定勢,陷入一個長時間的誤區,在那裡調試了半天,結果大腦一片混沌。睡覺前或者上下班路上一個人時,反而能想出一些新的思路和辦法。
3.開放地讨論。遇到問題不要不好意思,不管多簡單,多低級,隻要這個問題不是你google一下就能得到的結論,大膽地,認真地群組内同僚讨論。