PostgreSQL , 并行排序 , 外排 , merge sort , TOP-K , 并行创建索引 , 分区并行 , ranking , percent , midean , 数据分布
在OLAP场景,排序是一个非常重要的功能。也是衡量数据库是否适合OLAP场景的一个重要指标。例如这些场景:
1、求TOP-K,例如在对数据进行分组后,取出每个分组的TOP-K。
2、求中位数,要求对数据排序,并取出处于中间水位的值。
3、数据柱状图,需要对数据进行排序,并按记录均匀分割成若干BUCKET,获得bucket边界。
4、ranking排序,对数据进行排序,取出TOP-K。
5、数据按窗口分组,求数据分布,或groupAGG等。
<a href="https://www.postgresql.org/docs/devel/static/functions-window.html">https://www.postgresql.org/docs/devel/static/functions-window.html</a>
6、海量数据,取percent value,例如每一天的网站访问延迟水位数(99%, 95%, ......)。
7、创建索引(在TP场景,如果数据频繁更新删除,索引可能会逐渐膨胀,PG 11并行创建索引功能推出,索引维护性能杠杠的了(不堵塞DML的语法也支持并行, create index concurrently))。
排序能力真的很重要对吧,怪不得那么多企业参加计算机排序性能大赛呢。
PostgreSQL 11 在排序上有了长足的进步,支持了并行排序。
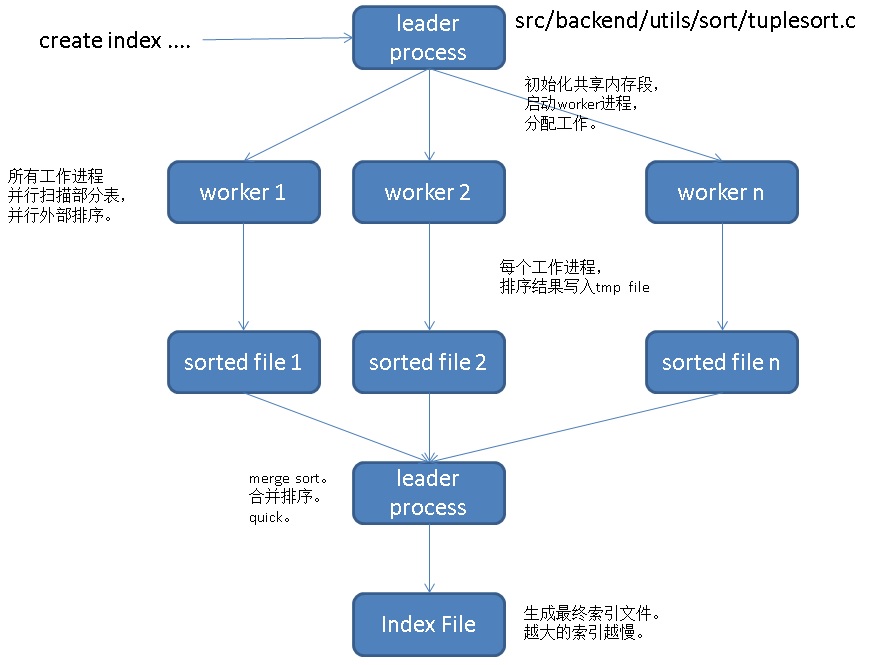
并行排序, 创建索引流程如下(并行扫描 -> 并行排序(阶段性quicksort+external sort) -> 合并排序并写索引文件),如果是求TOP-K,采用top-n heapsort并且不需要合并落盘的过程,爆快:
下面有一组测试数据,以及如何操纵并行排序的并行度,以及一些简单的原理介绍。有两个数字值得关注(也说明了PostgreSQL 进步飞速):
64线程,512G,NVME SSD
CentOS 7.x x64
PostgreSQL 11
一些预设参数,帮助控制并行度。
测试数据量1亿、10亿、100亿。排序字段为INT8类型。
1、表结构
2、使用dblink异步调用,并行加载数据。
3、创建生成dblink连接的函数,重复创建不报错。
4、并行加载1亿
5、并行加载10亿
6、并行加载100亿
非并行
并行(强制N个并行)
看一个执行计划,这个不涉及索引落盘,所以不受max_parallel_maintenance_workers参数控制,仅与其他几个并行参数相关。
为了保证每个Worker至少有32MB的内存用于并行排序,需要设置足够大的maintenance_work_mem(64个WORKER + 1 leader,至少需要2080MB内存)。
并行
PostgreSQL对分区表创建索引时,并不是所有分区同时并行开始创建(至少目前没有在内核中实现所有分区同时开始创建索引)。
但是,我们可以通过并行创建索引,控制每个分区的并行度。
让每个分区以16个并行度并行创建索引。
耗时与单表开64个并行差不多。(为什么不开64个并行,这里主要是因为分了4个分区,单分区数据量已经不大,16个并行度足矣。)
按照前面的测试,我们将100亿的表,分成100个分区,那么每个分区1亿数据,创建索引应该仅需1555秒(26分钟)。
并行排序,仅与这些参数有关:
具体并行度算法,参考:
<a href="https://github.com/digoal/blog/blob/master/201610/20161002_01.md">《PostgreSQL 9.6 并行计算 优化器算法浅析 - 以及如何强制并行度》</a>
1、基本参数,保证可以开足够多的并行计算worker进程数
2、成本模型,自动计算并行度
3、限定基于成本模型计算得到的并行度,单条创建索引SQL最大开多少个并行度
4、表上parallel_workers参数,覆盖根据成本模型计算得到的并行度(忽略max_parallel_maintenance_workers)
5、共享内存大小,每个创建索引的worker进程至少需要32MB,(注意还有一个leader process,因此为了保证开N个并行,那么需要 (N+1)*32MB ).
那么,要强制开N个并行创建索引,在满足条件1的情况下,只需要控制这两个参数maintenance_work_mem,以及表级parallel_workers。
用户可以自己去看文档
1、
<a href="https://www.postgresql.org/docs/devel/static/runtime-config-resource.html#GUC-MAX-PARALLEL-WORKERS-MAINTENANCE">https://www.postgresql.org/docs/devel/static/runtime-config-resource.html#GUC-MAX-PARALLEL-WORKERS-MAINTENANCE</a>
2、
<a href="https://www.postgresql.org/docs/devel/static/sql-createindex.html">https://www.postgresql.org/docs/devel/static/sql-createindex.html</a>
开启trace_sort可以跟踪排序过程。例子:
注意,以上提到的workMem,都是maintenance_work_mem决定的,除以(并行度+1)。
maintenance_work_mem的大小对并行创建索引的性能影响非常大。
想了解索引的内部构造、统计信息,可以使用pageinspect插件。
<a href="https://github.com/digoal/blog/blob/master/201605/20160528_01.md">《深入浅出PostgreSQL B-Tree索引结构》</a>
<a href="https://www.postgresql.org/docs/devel/static/pageinspect.html">https://www.postgresql.org/docs/devel/static/pageinspect.html</a>
<a href="https://github.com/digoal/blog/blob/master/201105/20110527_02.md">《Use pageinspect EXTENSION view PostgreSQL Page's raw infomation》</a>
用法这里不再赘述,可以看上面几篇文档。
PostgreSQL 11 内置了4种排序方法。
src/backend/utils/sort/tuplesort.c
数据量
结构
表占用空间
并行建索引占用空间
1亿
INT8+TEXT
4.2 GB
2.1 GB
10亿
41 GB
21 GB
100亿
413 GB
209 GB
硬件
非并行求TOP-K耗时
64并行度求TOP-K耗时
N倍性能
64线程机器
9.375 秒
0.5 秒
18.75 倍
95.16 秒
5.112 秒
18.615 倍
1107.55 秒
40 秒
27.69 倍
TOP-K用到的是top-N heapsort排序方法。
非并行创建索引耗时
64并行度创建索引耗时
性能提升倍数
26.244 秒
15.55 秒
1.69 倍
1442.7 秒
160.77 秒
8.97 倍
7456.9 秒
1869.5 秒
4 倍
并行创建索引用到的是external sorting algorithm 排序方法(external sort + external merge)。
由于并行创建索引分为并行扫描 -> 并行排序 -> merge的过程(merge阶段只有leader process在干活)。所以时间上并不是1亿(单进程)等于64亿(64并行)。
非并行的情况下,排序会随着记录数增多,非线性的增加耗时(26 -> 1442 -> 7456)。
并行的情况下,随着记录数增多,耗时基本是线性增加的,创建索引的基本时间可以预期(16 -> 161 -> 1870)。
值得注意的是,100亿时(创建索引耗时31分钟),并行过程IO已经开始有压力了(所有进程加起来写的文件已经超过400 GB),但是MERGE过程依旧是时间占比的大头。
PostgreSQL 每一个大版本都有令人非常惊喜的进步。单实例可以在26分钟(分区表)、31分钟(单表)左右创建一个100亿的索引。
maintenance_work_mem参数的大小对并行创建索引的性能影响较大。
目前PG暂时只支持BTREE索引的并行创建。期待后面加入另外N种(gin, hash, gist, sp-gist, brin, bloom)索引接口的并行创建。
<a href="https://github.com/digoal/blog/blob/master/201706/20170627_01.md">《PostgreSQL 9种索引的原理和应用场景》</a>
1、src/backend/utils/sort/tuplesort.c
2、src/include/utils/tuplesort.h
并行创建索引动作分解介绍:
![查找算法之二分查找查找算法之二分查找[图]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)