算法思想
- 希尔排序算法思想
-
使用一个增量序列{t1,t2,t3,......tn},其中tn>....>t2>t1=1,其实这个增量序列也可以理解为
间距序列;
设有数组A[k],下标从0开始:
当增量为tn时,从数组首元素A[0]开始,此时距离首元素间隔为tn的元素是A[tn],下一个距离元素A[tn]
间隔为tn的元素是A[tn*2],依次类推,从首元素开始间隔为tn的所有元素,A[0],A[tn],A[2*tn]....
A[x*tn]构成了一个分组,其中x*tn<k;
从数组第二个元素A[1]开始,此时距离A[1]间隔为tn的元素是
A[1+tn],下一个距离元素A[1+tn]间隔为tn的元素是A[1+tn*2],依次类推,从首元素开始间隔为tn的所
有元素,A[1],A[1+tn],A[1+2*tn]....A[1+x*tn]构成了一个分组,其中1+x*tn<k;
重复上述步骤,数组中所有的元素都被分组后,然后对每一个分组进行一次插入排序
取增量为tn-1,重复上述步骤进行分组,然后对每一个分组进行一次插入排序,直到取增量为t1时,此时数
组中的元素大致有序,在对整个数组进行一次插入排序,即可排序完成
-
-
算法图解
使用希尔排序对4,5,8,2,3,9,7,1进行排序,此时采用增量序列为{1,2,3},
当增量为3时:
当增量为2时: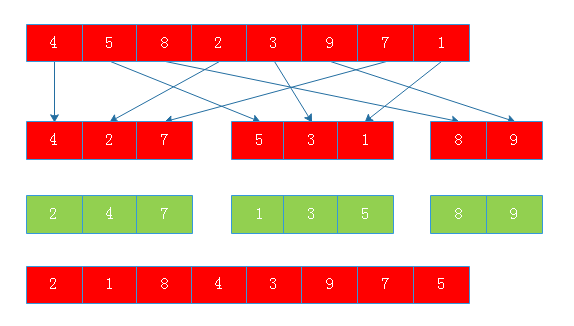
希尔排序 当增量为1时:
希尔排序 可以看出当增量为1时,待排序元素已经大致有序,此时进行一次插入排序即可完成排序 希尔排序 -
增量序列的选取
希尔排序是否高效取决于增量序列的选取,计算机科学家Knuth在《the art of compute programming》
中提出当相邻增量之间的比例为1:3时效果还行,也就是增量序列为{1,4,13,40,121,364,1093,.....}时
-
希尔排序和直接插入排序:
希尔排序是插入排序的扩展,插入排序每插入一次都要将插入位置以及它后面的元素整体向后进行一次平移,
例如,如果升序排序时,如果最小的元素在尾部,那么就需要N次才能将其插入到数组的首元素位置,这期间要
进行多次移动,希尔排序通过允许非相邻的等间距元素进行交换来减少插入排序频繁挪动元素的弊端。
代码实现
bool ShellSort(int * pUnSortAry, int nSize)
{
if (pUnSortAry == nullptr || nSize <= 0)
{
return false;
}
int nGrp = 0;
for (nGrp = 1; nGrp <= (nSize - 1) / 9; nGrp = nGrp * 3 + 1);
for ( ; nGrp >0; nGrp/=3)
{
for (int iIndex = nGrp; iIndex < nSize; iIndex++)
{
int nTemp = pUnSortAry[iIndex];
int jIndex = iIndex - nGrp;
for (; jIndex >= 0 && pUnSortAry[jIndex] > nTemp; jIndex -= nGrp)
{
pUnSortAry[jIndex+nGrp] = pUnSortAry[jIndex];
}
pUnSortAry[jIndex+nGrp] = nTemp;
}
}
return false;
}
测试代码:
int main()
{
srand(time(NULL));
int nArry[30] = { 0 };
for (int jIndex = 0; jIndex < 10; jIndex++)
{
for (int iIndex = 0; iIndex < sizeof(nArry) / sizeof(nArry[0]); iIndex++)
{
nArry[iIndex] = rand() % 150;
}
printf("排序前:");
PrintData(nArry, sizeof(nArry) / sizeof(nArry[0]));
ShellSort(nArry, sizeof(nArry) / sizeof(nArry[0]));
printf("排序后:");
PrintData(nArry, sizeof(nArry) / sizeof(nArry[0]));
}
return 0;
}
测试结果:
稳定性
希尔排序是将等距离的元素分为一组,相同的元素可能会被分到不同的组,在一个分组中的插入排序是文档的,
但是在多个分组多次插入排序的情况下可能会改变相同元素的相对位置,所以希尔排序是不稳定的排序